
Own The Way AI Discovers & Experiences Your Brand
Nudge helps you improve AI visibility and convert intent through shoppable funnels and personalized product experiences.






Track AI Mentions

Find out where you appear, how AI positions your brand, and which prompts you can win.
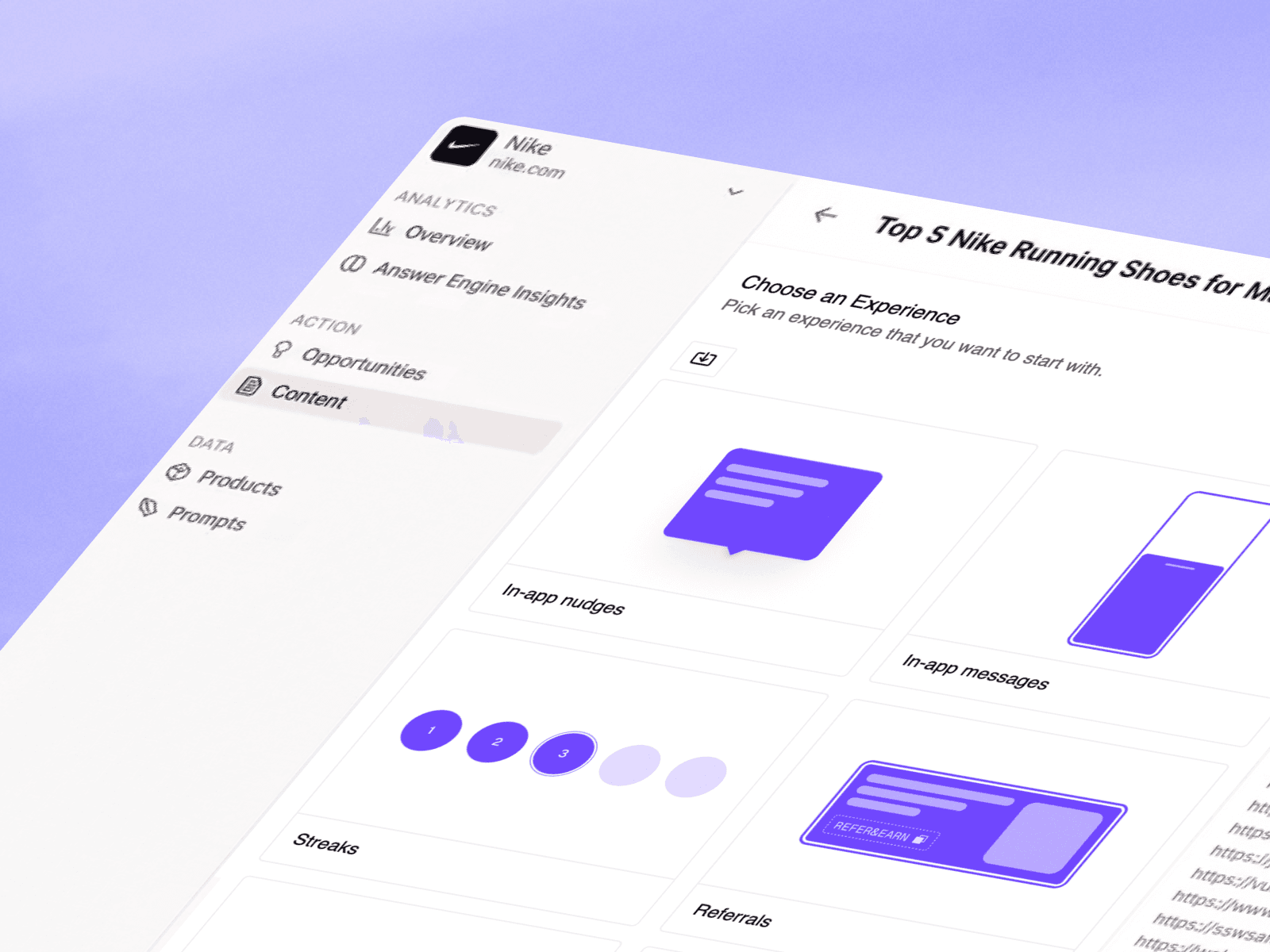
Turn Prompts into Funnels

Create shopping flows aligned to the decision criteria embedded in each AI query.
Elevate Product Ranking

Improve SKU-level inclusion by strengthening product details, claims, and use-case relevance.















Frequently asked questions
How does AEO work for commerce brands?
AEO helps brands show up in AI shopping answers. Nudge tracks how AI assistants interpret your brand and products, then helps you optimize content and product signals so you’re more likely to be recommended in high-intent queries.
How do I get started with Nudge?
Create your workspace, connect your store and catalog, and define a few high-value AI shopping prompts. Within days, you’ll see how your brand and products appear in AI answers and can start launching shoppable, prompt-specific funnels and pages.
What types of content can I create on Nudge?
You can create AI-optimized, prompt-specific shoppable pages, product comparison flows, and funnel-style experiences that get cited by AI assistants and are designed to educate shoppers & drive conversion.
What is the pricing for Nudge?
Nudge offers transparent pricing based on opportunities, number of prompts you want to track, and usage. Enterprise plans are available for larger brands. You can book a demo for a tailored quote!
How does Nudge assess AI visibility?
Nudge analyzes AI-generated shopping answers across leading models to see where your brand and products appear, how they’re described, and where opportunities exist to improve visibility.
What is AI search visibility?
AI search visibility is how often and how prominently your brand or products appear in AI answers on platforms like ChatGPT, Rufus, or Perplexity. For commerce brands, this matters because the first moment of intent is shifting upstream and purchase decisions are increasingly shaped before a shopper visits your site. AI visibility influences consideration, traffic quality, and ultimately revenue.
How does Nudge assess AI visibility?
Nudge is built specifically for commerce teams. We combine AI visibility tracking, SKU-level catalog optimization, and conversion-focused page creation in one platform, helping brands move from recommendation to purchase across both in-chat and click-out shopping journeys.
